Overview
When I began using R, like most researchers I kept all my data in some combination of R’s native data.frame format or a CSV file that my analysis would continually read. However, as I began to analyze big datasets at the SAPA Project and at Insight, I realized that there is a lot of value to instead keeping your data in a MySQL database and streaming it into R when necessary. This post will briefly outline a few advantages of using a database to store data and run through a basic example of using R to transfer data to MySQL.
Memory Efficiency
Relational databases, such as MySQL, organize data into tables (like a spreadsheet) and can link values in tables to each other. Generally speaking, they are better at handling large datasets and are more efficient at storing and accessing data than CSVs due to compression and indexing. The data stay in the MySQL database until accessed via a query, which is different than how R approaches data.frames and CSVs. When accessing data stored in a data.frame or CSV file in R, the data must all fit in memory. However, this becomes a problem if when using a large dataset or if you’re cursed with an older computer with <= 4GB of RAM. In these cases, every time you load your dataset or do a memory-intensive operation (e.g., polychoric correlations) your computer will slow to a painful crawl as your hard drives grind while your operating system switches to using virtual memory or swap space, rather than RAM. You could get around this by using random sampling to create a smaller subset (or multiple subsets if you want to bootstrap), but you can also use this technique on a SQL database. The advantage is that SQL databases only load the data you’re working with into your local machine’s RAM when you SELECT the data you need - leaving plenty of memory for the actual analysis.
Safety and Security
Two additional reasons I prefer SQL databases are safety and security. Services such as Amazon’s RDS (i.e., Relational Database Service) offer frequent backups and easy replication across instances. If the local machine dies, the data are safe and uncorrupted. If I were storing data in an .Rdata file, I’d have to rely on my OS (e.g., Time Machine) or a cloud-based storage solution (e.g., Dropbox or CrashPlan) to backup my data. Worse, if I were storing my data in an Excel database and Excel crashed, I may risk losing years of progress.
Using MySQL, I can give a collaborator access to only needed portions of the data by locking down their SQL user to certain tables and operations. By limiting access, we limit risk of corruption and overwriting years of progress.
Scalable as the need grows
Last, I find databases such as MySQL to be more scalable due to cloud computing. In the case of using Amazon’s RDS, you can buy as much storage or bandwidth as you need to complete your analysis, dissertation, or build your web app. If I need multiple nodes or machines to analyze the data, I don’t need to keep a copy of the data on each machine. I simply pass the SQL authentication parameters to each machine and the data is accessed from a central location.
So let’s begin by setting up a Free-Tier RDS service on Amazon and then move some data from R to the RDS database.
Setting up an RDS Instance
Amazon currently offers a Free Tier for their RDS storage. It offers:
- Enough hours to run a DB Instance continuously each month,
- 20 GB of database storage,
- 10 million I/O operations, and
- automated database backups.
To setup an RDS instance:
- Sign into the AWS Management Console.
- Select ‘RDS’ under the ‘Database’ group.
- Click ‘Launch DB Instance’.
- Select ‘MySQL’ for the database engine.
- Select ‘No’ when asked if you intend to use the database for production purposes. Accidentally selecting ‘Yes’ could result in hefty fees.
- For ‘Instance Class’, select ‘db.t1.micro’, ‘No’ for ‘Multi-AZ Deployment’, and 20 GB for ‘Allocated Storage’.
- Click ‘Next’ and launch your RDS instance.
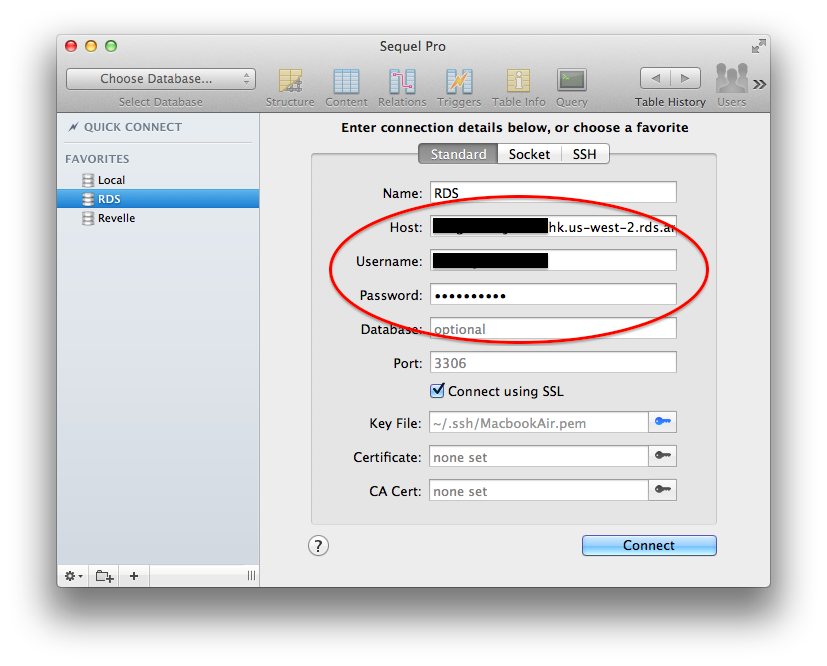
At this point, you should have a blank RDS database with a master username and password combination. Be sure to test that you can connect - I suggest using Sequel Pro. If you can’t connect, you may need to open up port 3306 in your EC2 Security Group.
Click on your new RDS Instance to get the hostname to connect to and note the database name:
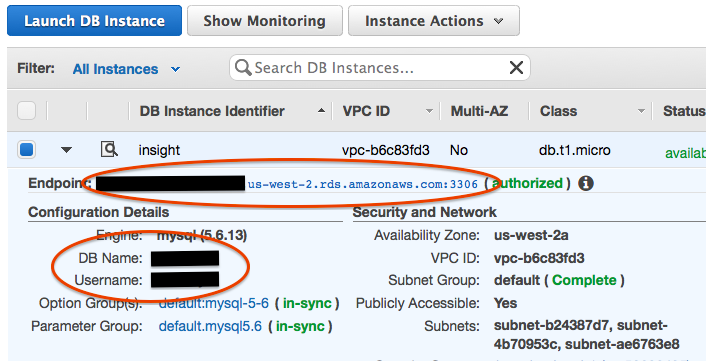
Fire up Sequel Pro and test out your new database. If you want to connect using SSL, you’ll need the SSH key you generated when you first created your EC2 instance (not covered here).
Installing the RMySQL package
Previously, I found installing RMySQL to be very difficult when I was using MacPorts. However,
having switched to Homebrew on my new machine, RMySQL found all the MySQL headers and libraries as
Homebrew uses the /usr/local directory to store your software, which is already in your shell $PATH.
Before compiling RMySQL, first compile MySQL using Homebrew:
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Next, compile RMySQL from source:
1
| |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | |
Transferring Existing Data to/from MySQL
Having a database is useless unless we can easily convert our existing data.frames
into MySQL tables. Let’s try this using the Thurstone dataset from the Revelle’s psych package:
1 2 3 4 5 6 7 8 | |
There! Now we have transferred our data.frame to our SQL database.
Similarly, if you want to read data from MySQL to R, we can use the dbReadTable() function,
which returns a data.frame object. You can keep your data in MySQL and stream portions into R for specific analyses.
Since dbReadTable outputs a data.frame, we can use this command in place of a data.frame.
Let’s run an omega() factor analysis on the Thurstone table:
1
| |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | |
In other analyses, you may only need a fraction of the MySQL table. In these cases, we’d want to use the dbGetQuery() command and issue a MySQL statement to SELECT and aggregate the information. Let’s get a vector of Sentences correlations that are greater than 0.5:
1
| |
1 2 3 4 5 | |
Safely storing credentials
It’s important to note that in the above example, although I passed the user and password
parameters within my dbConnect() function, you would never want to do this in production code that
you were sharing. It’s far better to store the credentials a text file where dbConnect(MySQL()) will look when you don’t pass any credentials:
1 2 3 4 | |
Useful Packages for Fast DB Operations
Ideally, we want to have one set of analysis code that is agnostic to how
the data are stored. I suggest looking into Hadley Wickham’s new dplyr package
(Github). dplyr is able to filter, sort, group, and summarize data
quickly whether it is stored in a data.frame, data.table, or database. Database operations may not always be as
fast as a data.table operation, but again, the advantage is that you don’t need to feed all of your data into memory.
Hadley provides a few vignettes for getting getting started with dplyr:
1 2 | |